

Bobsled, a startup building a platform for sharing data across the cloud, today announced that it has raised a $17 million Series A funding round led by Greycroft and Madrona Venture Group. This round follows a $7 million seed round led by .406 Ventures. In this latest round, Bobsled was valuationd at $87 million.
Prior to founding Bobsled in late 2021, company CEO and co-founder Jake Graham was the lead product manager at Microsoft Azure, working on Azure Data Exchange. Graham, who also previously worked at Neo4j and Intel, believes data sharing will be a fundamental change in the analytics landscape.
“It’s the next evolution of how companies can actually access the data they need to drive machine learning analytics, data science, what have you,” he said. “I’ve been building in the data infrastructure space for about a decade, and APIs and SFTP being the way data gets transferred was just one of those things that I accepted. It wasn’t until I really started digging into it: It shouldn’t be. It doesn’t make sense. It was designed for an earlier model of data.”
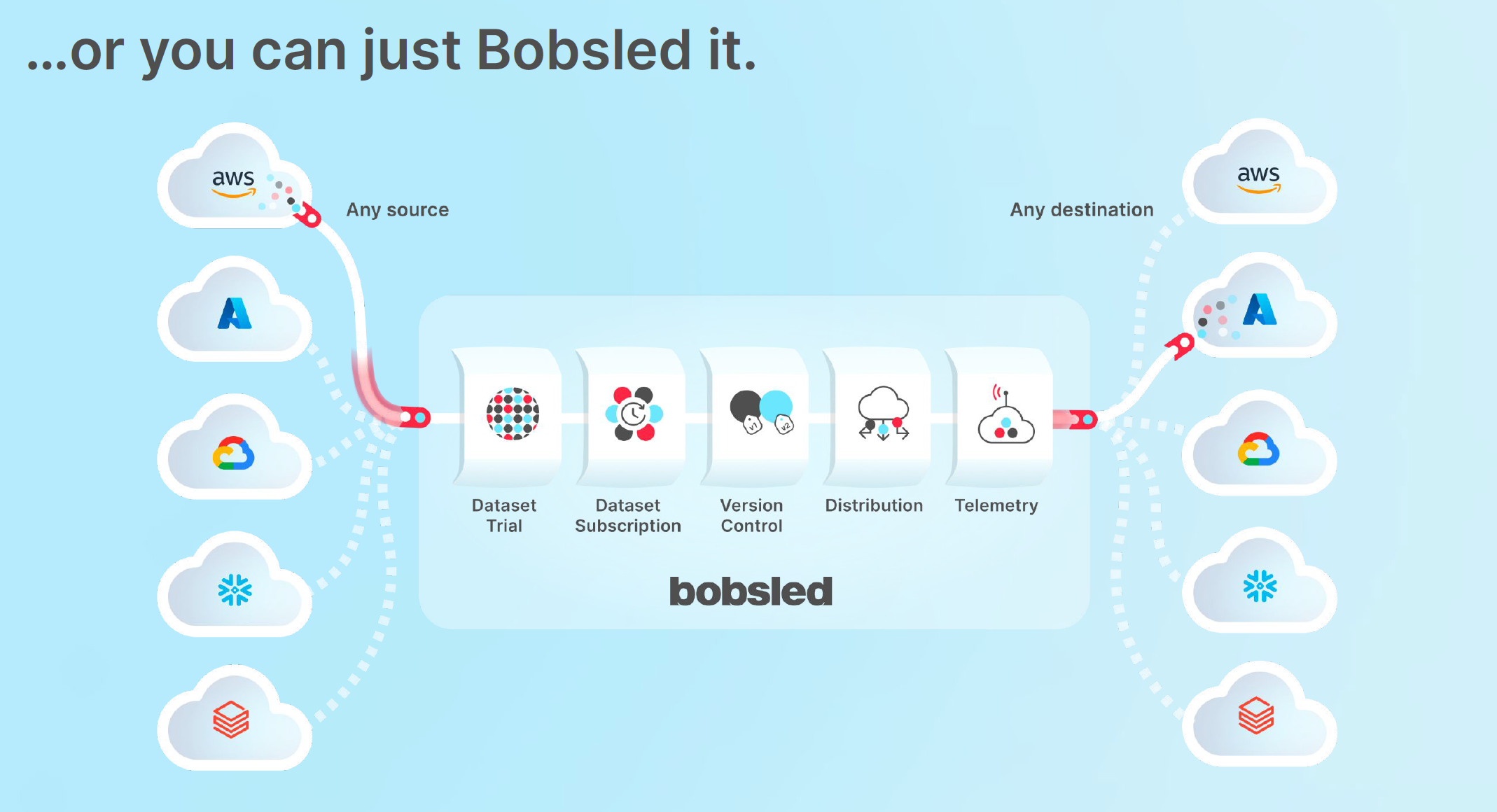
Image credits: sleigh
Graham also believes that it is important for the cloud and data platform to create the building blocks of what a native sharing protocol should look like.
“If you think that sharing data is the way the world works and that there will be more active collaboration on data between source and destination, then you need something that brings all these different platforms together, because there is no one right cloud, no one right data warehouse. There is no single proper layer of the stack to make data sharing happen,” he said.
Bobsled believes, unsurprisingly, that it could be this third-party data sharing platform that could allow companies to connect their different data sources in a more authentic way. The service uses each platform’s sharing protocol and then connects the different sources and helps companies prepare datasets to query.

Image credits: sleigh
Some common use cases here are SaaS applications that might want to share application data from AWS S3 into a customer’s Azure storage, for example, or a data team that wants to move sales data from Azure to S3 for analysis.
Obviously, there are other companies that focus on this kind of data transfer and data transformation space. But Graham believes that with ELT platforms like Fivetran, the consumer still has a lot of work to do. “The data source has to do a lot of what English language teaching platforms do,” he said. “So we’re switching to leaving a lot of that. If you separate characters, extract: You do that because it’s not shared with you. Payload? Same thing. If you get share inside Databricks, nothing gets loaded.” As for transforming the data, he noted that most of the time the data is in a transactional data form that needs a format for parsing and that data must be transformed by the source—although he believes that transforming data from multiple data sources to match a particular schema will always be up to the consumer.
“I wouldn’t call us directly an ELT product yet because we’re different enough, but I think that’s the closest thing to the class we’re building. It’s just a different user,” Graham explained.
The company plans to use the new funding to build out its platform, mostly focusing on supporting more data sources (including legacy SFTP sources).
“The promise of AI increases the urgency and increases the priority for companies to realize the value of their data,” said S. Somasegar, Managing Director, Madrona. Even within organizations and between partners, this data is now spread across platforms that are not designed to work together. sleighThe unique focus of data sharing through the cloud will unlock data value that has been complex, slow and expensive to access until now.”